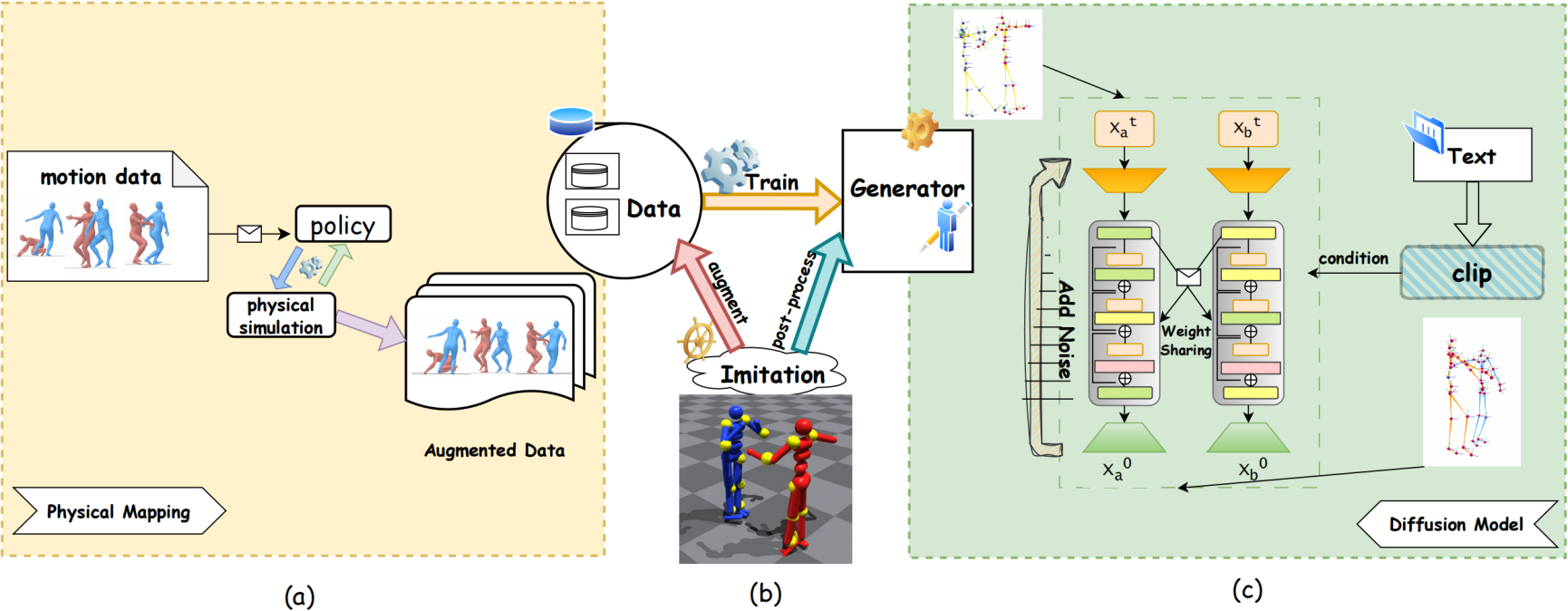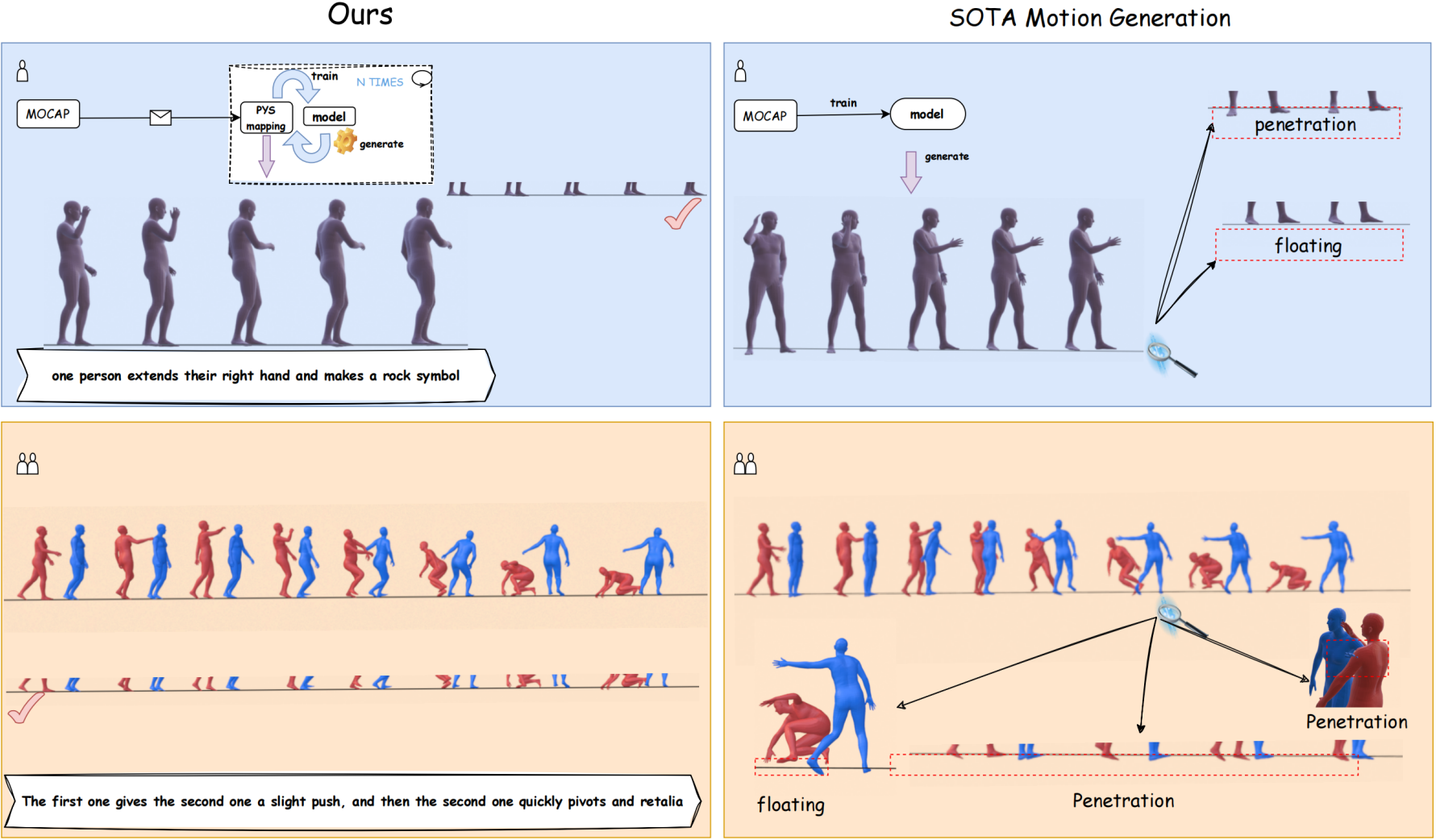
—Driven by advancements in motion capture and generative artificial intelligence, leveraging large-scale MoCap datasets to train generative models for synthesizing diverse, realistic human motions has become a promising research direction. However, existing motion-capture techniques and generative models often neglect physical constraints, leading to artifacts such as interpenetration, sliding, and floating. These issues are exacerbated in multi-person motion generation, where complex interactions are involved. To address these limitations, we introduce physical mapping, integrated throughout the human interaction generation pipeline. Specifically, motion imitation within a physics-based simulation environment is used to project target motions into a physically valid space. The resulting motions are adjusted to adhere to real-world physics constraints while retaining their original semantic meaning. This mapping not only improves MoCap data quality but also directly informs post-processing of generated motions. Given the unique interactivity of multi-person scenarios, we propose a tailored motion representation framework. Motion Consistency (MC) and Marker-based Interaction (MI) loss functions are introduced to improve model performance. Experiments show our method achieves impressive results in generated human motion quality, with a 3%–89% improvement in physical fidelity.
@article{yao2025p,
title={PhysiInter: Integrating Physical Mapping for High-Fidelity Human Interaction Generation},
author={Yao, Wei and Sun, Yunlian and Liu, Chang and Zhang, Hongwen and Tang, Jinhui},
journal={arXiv preprint arXiv:2506.07456},
year={2025}
}
[1] Liang H, Zhang W, Li W, et al. Intergen: Diffusion-based multi-human motion generation under complex interactions[J]. International Journal of Computer Vision, 2024, 132(9): 3463-3483.
[2] Tevet G, Raab S, Gordon B, et al. Human motion diffusion model[J]. arXiv preprint arXiv:2209.14916, 2022.