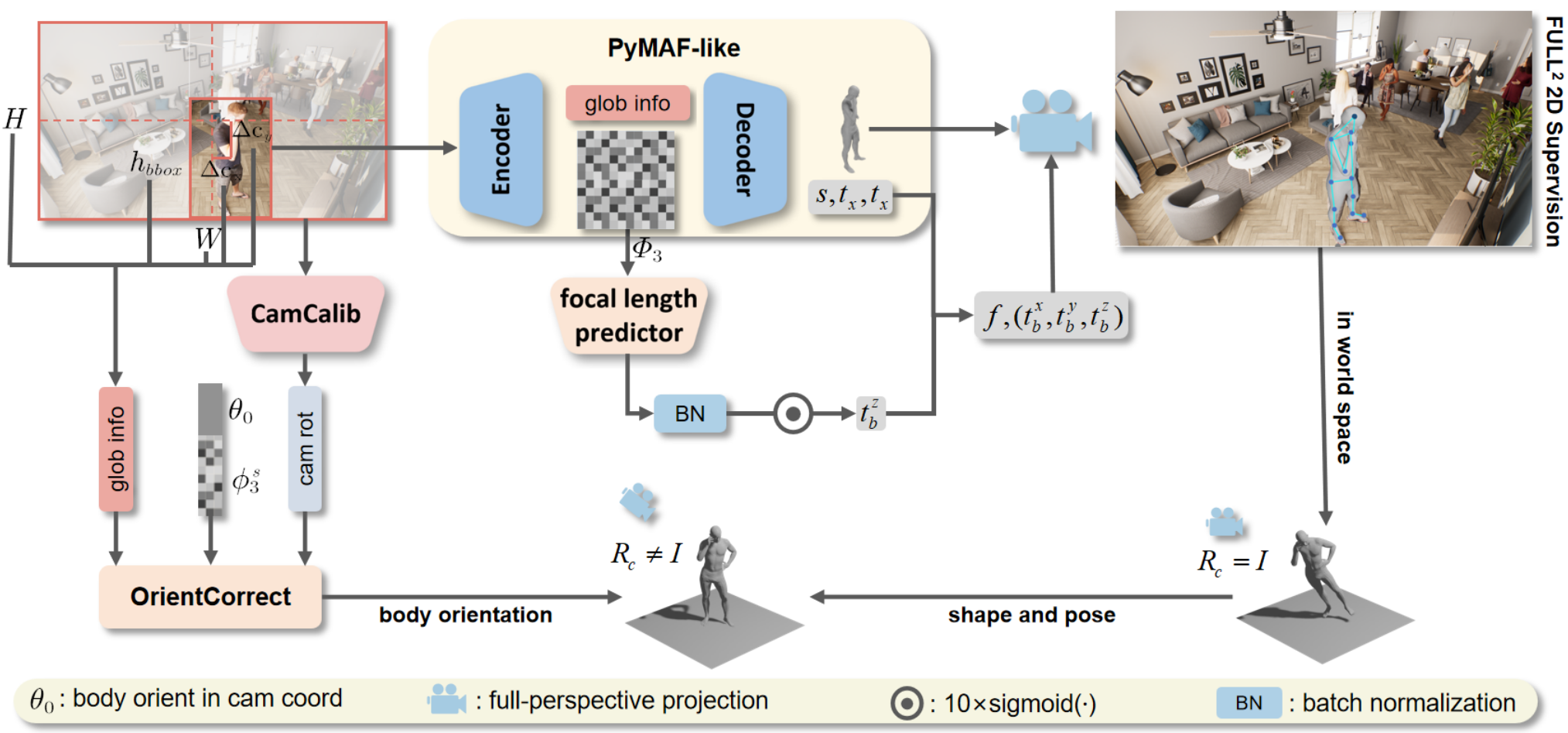
—Previous methods for 3D human motion recovery from monocular images often fall short due to reliance on camera coordinates, leading to inaccuracies in real-world applications. The limited availability and diversity of focal length labels further exacerbate misalignment issues in reconstructed 3D human bodies. To address these challenges, we introduce W-HMR, a weak-supervised calibration method that predicts “reasonable” focal lengths based on body distortion information, eliminating the need for precise focal length labels. Our approach enhances 2D supervision precision and recovery accuracy. Additionally, we present the OrientCorrect module, which corrects body orientation for plausible reconstructions in world space, avoiding the error accumulation associated with inaccurate camera rotation predictions. Our contributions include a novel weak-supervised camera calibration technique, an effective orientation correction module, and a decoupling strategy that significantly improves the generalizability and accuracy of human motion recovery in both camera and world coordinates. The robustness of W-HMR is validated through extensive experiments on various datasets, showcasing its superiority over existing methods. Codes and demos have been made available on the project page.
@article{yao2023w,
title={W-HMR: Monocular Human Mesh Recovery in World Space with Weak-Supervised Calibration},
author={Yao, Wei and Zhang, Hongwen and Sun, Yunlian and Liu, Yebin and Tang, Jinhui},
journal={arXiv preprint arXiv:2311.17460},
year={2023}
}
[1] Ailing Zeng, Lei Yang, Xuan Ju, Jiefeng Li, Jianyi Wang, and Qiang Xu. SmoothNet: A plug-and-play network for refining human poses in videos. In European Conference on Computer Vision (ECCV), volume 13665, pages 625–642, 2022.
[2] Muhammed Kocabas, Chun-Hao P Huang, Joachim Tesch, Lea M ̈uller, Otmar Hilliges, and Michael J Black. Spec: Seeing people in the wild with an estimated camera. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 11035–11045, 2021b
